ITSM initiatives often focus heavily on operational requirements, without paying enough up-front attention to reporting and analytics. This can lead to increased difficulty after go-live, and lost opportunity for optimisation. Big data is a huge and important trend, but don’t forget that a proactive approach to ordinary reporting can be very valuable.
“…users must spend months fighting for a desired report, or hours jockeying Excel spreadsheets to get the data they need. I can only imagine the millions of hours of productive time spent each month by people doing the Excel “hokey pokey” each month to generate a management report that IT has deemed not worthwhile”
Don’t Forget About “Small Data” – Patrick Gray in TechRepublic
In a previous role, aligning toolsets to processes in support of our organisation’s ITSM transformation, my teammates and I used to offer each other one piece of jokey advice: “Never tell anyone you’re good with Crystal Reports”.
The reason? Our well established helpdesk, problem and change management tool had become a powerful source of management reports. Process owners and team managers wanted to arrive at meetings armed with knowledge and statistics, and they had learned that my team was a valuable data source.
Unfortunately, we probably made it look easier than it actually was. These reports became a real burden to our team, consuming too much time, at inconvenient times. “I need this report in two hours” often meant two hours of near-panic, delving into data which hadn’t been designed to support the desired end result. We quickly needed to reset expectations. It was an important lesson about reporting.
Years later, I still frequently see this situation occurring in the ITSM community. When ITSM initiatives are established, processes implemented, and toolsets rolled out, it is still uncommon for reporting to be considered in-depth at the requirements gathering stage. Perhaps this is because reporting is not a critical-path item in the implementation: instead, it can be pushed to the post-rollout phase, and worried about later.
One obvious reason why this is a mistake is that many of the things that we might need to report on will require specific data tracking. If, for example, we wish to track average assignment durations, as a ticket moves between different teams, then we have to capture the start and end times of each. If we need to report in terms of each team’s actual business hours (perhaps one team works 24/7, while another is 9 to 5), then that’s important too. If this data is not explicitly captured in the history of each record, then retrospectively analysing it can be surprisingly difficult, or even impossible.
Consider the lifecycle of a typical ITSM data instance, such as an incident ticket:
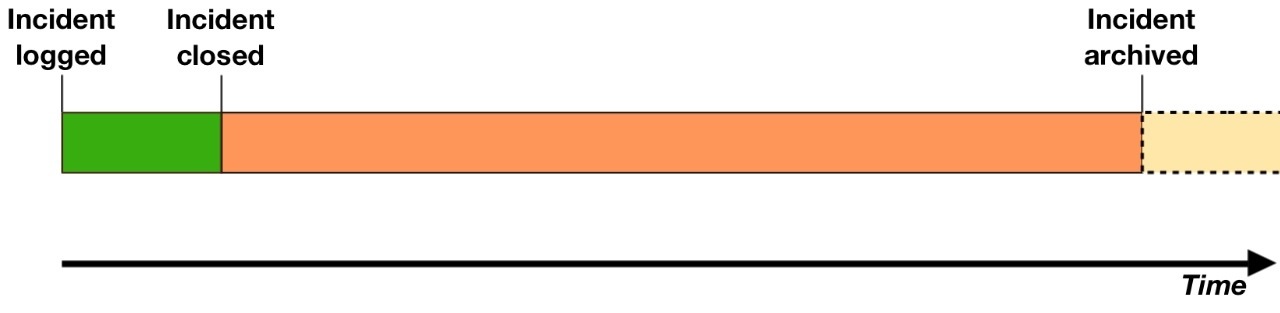
Our record effectively moves through three stages:
- 1: The live stage
This is the key part of an incident’s record’s life, in which it is highly important as a piece of data in its own right. At this point, there is an active situation being managed. The attributes of the object define where it is in the process, who owns it, what priority it should take over other work, and what still needs to be done. This phase could be weeks long, near-instantaneous, or anything between. - 2: The post-live stage
At this point, the ticket is closed, and becomes just another one of the many (perhaps hundreds of thousands) incidents which are no longer actively being worked. Barring a follow up enquiry, it is unlikely that the incident will ever be opened and inspected by an individual again. However, this does not mean that it has no value. Incidents (and other data) in this lifecycle phase do not have much significant value in their own individual right (they are simply anecdotal records of a single scenario), but together they make up a body of statistical data that is, arguably, one of the IT department’s most valuable proactive assets. - 3: The archived stage
We probably don’t want to keep all our data for ever. At some stage, the usefulness of the data for active reporting diminishes, and we move it to a location where it will no longer slow down our queries or take up valuable production storage.
It’s important to remember that our ITSM investment is not just about fighting fires. Consider two statements about parts of the ITIL framework (these happen to be taken from Wikipedia, but they each seem to be very reasonable statements):
Firstly, for Incident Management:
“The objective of incident management is to restore normal operations as quickly as possible”
And, for Problem Management:
“The problem-management process is intended to reduce the number and severity of incidents and problems on the business”
In each case, the value of our “phase 2” data is considerable. Statistical analysis of the way incidents are managed – the assignment patterns, response times and reassignment counts, first-time closure rates, etc. – helps us to identify the strong and weak links of our incident process in a way that no individual record can do so. Delving into the actual details of those incidents in a similar way helps us to identify what is actually causing our issues, reinforcing Problem Management.
It’s important to remember that this is one of the major objectives of our ITSM systems, and a key basis of the return on our investment. We can avoid missing out on this opportunity by following some core principles:
- Give output requirements as much prominence as operational requirements, in any project’s scope.
- Ensure each stakeholder’s individual reporting and analytics needs are understood and accounted for.
- Identify the data that actually needs to be recorded, and ensure that it gets gathered.
- Quantify the benefits that we need to get from our analytics, and monitor progress against them after go-live.
- Ensure that archiving strategies support reporting requirements.
Graphs icon courtesy of RambergMediaImages on Flickr, used under Creative Commons licensing.