Does your organization understand the real costs of the congestion suffered by your IT services? Effective management and avoidance of congestion can deliver better service and reduced costs, but some solutions can be tough to sell to customers.
The Externalities of Congestion
In 2009, transport analyst and activist Charles Komanoff published, in an astonishingly detailed spreadsheet, his Balanced Transportation Analysis for New York City. His aim was to explore the negative external costs caused by the vehicular traffic trying to squeeze into the most congested parts of the city each day.
His conclusion? In the busiest time periods, each car entering the business district generates congestion costs of over $150.

- Congestion Costs outlined in Komanoff’s Balanced Transportation Analysis

Komanoff’s spreadsheet can be downloaded directly here. Please be warned: it’s a beast – over three megabytes of extremely complex and intricate analysis. Reuters write Felix Salmon succinctly stated that “you really need Komanoff himself to walk you through it“.
Komanoff’s work drills into the effect of each vehicle moving into the Manhattan business district at different times of day, analyzing the cascading impact of each vehicle on the other occupants of the city. The specific delays caused by any given car on any other given vehicle is probably tiny, but the cumulative effect is huge.
The Externalities of Congested IT Services
Komanoff’s city analysis models the financial impact of a delay to each vehicle, such as commercial vehicles, carring several paid professionals, travelling to fulfil charged-for business services. With uncontrolled access to the city, there is no consideration of the “value” of each journey, and thus high-value traffic (perhaps a delivery of expensive retail goods to an out-of-stock outlet) gets no prioritization over any lower value journey.
Congested access to IT resources, such as the Service Desk, has equivalent effects. Imagine a retail unit losing its point-of-sale systems on the Monday morning that a HQ staff return from their Christmas vacation. The shop manager’s frantic call may find itself queued behind dozens of forgotten passwords. Ten minutes of lost shop business will probably cost far more than a ten minute delay in unlocking user accounts.
That’s not to say that each password reset isn’t important. But in a congested situation, each caller is impacted by, and impacts, the other people calling in at the same time.
The dynamics and theory of demand management in call centers have been extensively studied and can be extremely complex (a google search reveals plentiful studies, often with complex and deep mathematical analysis. This is a by no means the most example!).
Fortunately, we can illustrate the effects of congestion with a relatively simple model.
Our example has the following components:
- Four incoming call lines, each manned by an agent
- A group of fifteen customers, dialling-in at or after 9am, with incidents which each take 4 minutes for the agent to resolve.
- Calls arriving at discrete 2-minute intervals (this is the main simplification, but for the purposes of this model, it suffices!)
- A call queuing system which can line up unanswered calls.
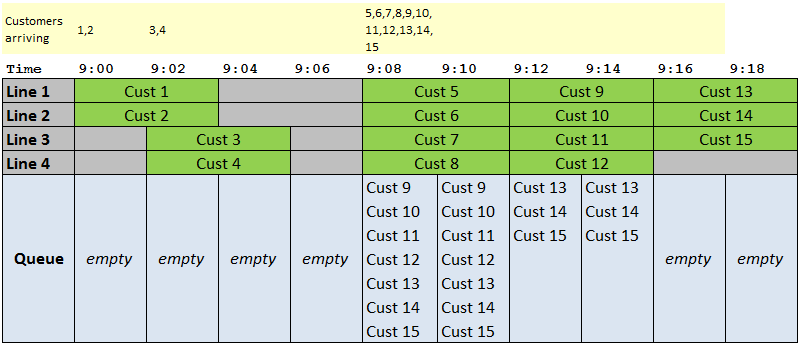
When three of our customers call in each 2-minute period, we quickly start to build up a backlog of calls:

We’ve got through the callers in a relatively short time (everything is resolved by 09:16). However, that has come at a price: 30 customer-minutes of waiting time.
If we spread out the demand slightly, and assume that only two customers call in at the start of each two-minute period, however, the difference is impressive:

Although a few users (customers 3,7, 11 and 15) get their issues resolved a couple of minutes later in absolute terms, there is no hold time, for anyone. Assuming there are more productive things a user can be doing other than waiting on hold (notwithstanding their outstanding incident), the gains are clear. In the congestion scenario, the company has lost half an hour of labour, to no significant positive end.
Of course, while Komanoff’s analysis is comprehensive, it is one single model and can’t be assumed completely definitive. But it is undeniable that congestion imposes externalities.
Komanoff’s proposed solution involves a number of factors, including:
- A congestion charge, applying at all levels of day, with varying rates, applying to anyone wishing to bring a car into the central area of the city.
- Variable pricing on some alternative transportation methods such as trains, with very low fares at off-peak times.
- Completely free bus transport at ALL times.
Congestion management of this kind is nothing new, of course. London, having failed to capitalize on its one big chance to remodel its ancient street layout, introduced a central, flat-fare central congestion charge in 2003. Other cities have followed suit (although proposals in New York have not come to fruition). Peak time rail fares and bridge tolls are familiar concepts in many parts of the world. Telecoms, the holiday industry, and numerous other sectors vary their pricing according to periodic demand.
Congestion Charging in IT?
Presumably, then, we can apply the principles of congestion charging to contested IT resources, implementing a variable cost model to smooth demand? In the case of the Service Desk, this may not always be straightforward, simply because in many cases the billing system is not a straightforward “per call” model. And in any case, how will the customer see such a proposal?
Nobel Laureate William S. Vickery is often described as “the father of congestion charging”, having originally proposed it for New York in 1952. Addressing the objections to his idea, he said:
“People see it as a tax increase, which I think is a gut reaction. When motorists’ time is considered, it’s really a savings.”
If the customer agrees, then demand-based pricing could indeed be a solution. A higher price at peak times could discourage lower priority calls, while still representing sufficient value to those needing more urgent attention. This model will increasingly be seen for other IT services such as cloud-based infrastructure.
There are still some big challenges, though. Vickrey’s principles included the need to vary prices smoothly over time. If prices suddenly fall at the end of a peak period, this generates spikes in demand which themselves may cause congestion. In fact, as our model shows, the impact can be worse than with no control at all:
This effect is familiar to many train commuters (the 09:32 train from Reading to London, here in the UK, is the first off-peak service of the morning, and hence one of the most crowded). However, implementing smooth pricing transitions can be complex and confusing compared to more easily understood fixed price brackets.
Amazon’s spot pricing of its EC2 service is an interesting alternative. In effect, it’s still congestion pricing, but it’s set by the customer, who is able to bid their own price for spare capacity on the Amazon cloud.
Alternatives?
Even if the service is not priced in a manner that can be restructured in this way, or if the proposition is not acceptable to the customer, there are still other options.
Just as Komanoff proposes a range of positive and negative inducements to draw people away from the congested peak-time roads, an IT department might consider a range of options, such as:
- Implementation of a service credits system, where customers are given a positive inducement to access the service at lower demand periods, could enable the provider to enhance the overall service provided, with the savings from congestion reduction passed directly to the consumer.
- Prioritization of access, whereby critical tasks are fast-tracked in priority to more routine activities.
- Varieable Service Level Agreements, offering faster turnarounds of routine requests at off-peak times. Again, if we can realise Vickrey’s net overall saving, it may be possible to show enhanced overall service without increased overall costs.
- Customer-driven work scheduling. Apple’s Genius Bar encourages customers to book timeslots in advance. This may result in a longer time to resolution than a first-come-first-served queue, but it also gives the customer the opportunity to choose a specific time that may be more convenient to them anyway. Spare capacity still allows “walk up” service to be provided, but this may involve a wait.
- Customer self-service solutions such as BMC’s Service Request Management. Frankly, this should be a no-brainer for many organizations. If we have an effective solution which allows customers to both log and fulfil their own requests, we can probably cut a significant number of our 15 customer calls altogether. Self-service systems offer much more parallel management of requests, so if all 15 customers hit our system at once, we’d not expect that to cause any issue.
Of course, there remains the option of spending more to provide a broader capacity, whether this is the expansion of a helpdesk or the widening of roads in a city. However, when effective congestion management can be shown to provide positive outcomes from unexpanded infrastructure, shouldn’t this be the last resort?
(congestion charge sign photo courtesy of mariodoro on Flickr, used under Creative Commons licensing)